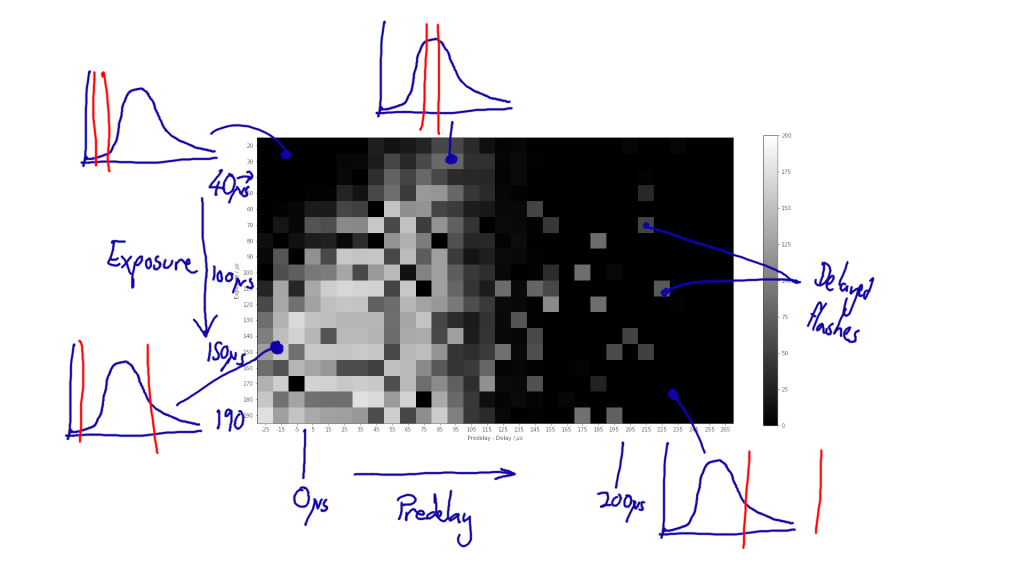
tldr; for MCMC for VI use the posterior covariance of q(u) from an initial standard-VI run to whiten the latent variables, rather than use the prior covariance?
I’m new to both Variational Inference and MCMC/HMC but I’ve already experienced the well known issues associated with each.
- Variational Inference is well known for being poor at properly quantifying the uncertainty,
we do know that variational inference generally underestimates the variance of the posterior density; this is a consequence of its objective function. But, depending on the task at hand, underestimating the variance may be acceptable [1]
- HMC/MCMC often struggles with Gaussian process models,
The common approach to inference for latent Gaussian models is Markov chain Monte Carlo (MCMC) sampling. It is well known, however, that MCMC methods tend to exhibit poor performance when applied to such models. Various factors explain this. First, the components of the latent field  are strongly dependent on each other. Second,
are strongly dependent on each other. Second,  and are also strongly dependent, especially when
and are also strongly dependent, especially when  is large. [2]
is large. [2]
One solution is to “whiten” the latent variables for the HMC decorrelating them. This is described in [3] and was also suggested to me in this github issue. In both the prior covariance matrix is used to initially transform the latent variables.
In my application however I’ve found that isn’t sufficient. My application is calibrating lots of [low cost] air pollution sensors scattered across a city (one or two sensors are ‘reference’ and are assumed to give correct measurements). Some sensors can move & it’s assumed when sensors are colocated they’re measuring the same thing. In my model each sensor has a transformation function (parameterised by a series of correlated random variables that have GP priors, over time) this function describes the scaling etc that the cheap sensors do to the real data. We assume these can drift over time. For now imagine this is just a ‘calibration scaling’ each sensor needs to apply to the raw signal to get the ‘true’ pollution, at a given time.
A-priori the scaling for each sensor is assumed to be independent, but once two sensors (A & B) have been in proximity their (posterior) scalings are very very correlated. If B is colocated with sensor C and C with D, etc, it will lead to very strong correlations in these scaling variables across the network. Importantly these correlations are induced by the observations and are only in the posterior, not the prior. The upshot is that the whitening provided by the prior covariance doesn’t help decorrelate the latent variables much, and I found the HMC really struggled to mix.
The Idea
I was thinking an obvious solution is to run ‘normal’ Variational Inference first, using a standard multivariate Gaussian for the approximating distribution, q(u). Then, once it’s (very) roughly optimised, use the covariance from q(u) instead of the covariance from the prior for whitening. This way we hopefully will have the benefit of a complicated distribution provided by HMC but it can still sample/mix successfully.
[1] Blei, David M., Alp Kucukelbir, and Jon D. McAuliffe. “Variational inference: A review for statisticians.” Journal of the American statistical Association 112.518 (2017): 859-877. link
[2] Rue, Håvard, Sara Martino, and Nicolas Chopin. “Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations.” Journal of the royal statistical society: Series b (statistical methodology) 71.2 (2009): 319-392. link
[3] Hensman, James, et al. “MCMC for variationally sparse Gaussian processes.” Advances in Neural Information Processing Systems. 2015. link















{kind=link}