Note for self:
Just type
debug
in the next cell. (u = up, c = continue)
Use:
import pdb; pdb.set_trace()
to add a trace point to your code.
Note for self:
Just type
debug
in the next cell. (u = up, c = continue)
Use:
import pdb; pdb.set_trace()
to add a trace point to your code.
A linear model with GPy.
Background: I’m working on a project aiming to extrapolate dialysis patient results over a 100-hour window (I’ll write future blog posts on this!). I’m working with James Fotheringham (Consultant Nephrologist) who brilliantly bridges the gap between clinic and research – allowing ivory-tower researchers (me) to get our expertise applied in the real world to useful applications.
Part of this project is the prediction of the patient’s weight. We’ll consider a simple model.
When a patient has haemodialysis, they will have fluid removed. If this doesn’t happen frequently or successfully enough the patient can experience *fluid overload*. Each dialysis session (in this simplified model) brings the patient’s weight back down to their dry-weight. Then this weight will increase (roughly linearly) as time goes by until their next dialysis session. I model their weight \(w(t,s)\) with a slow-moving function of time-since-start-of-trial, \(f(t)\), added to a linear function of time-since-last-dialysis-session, \(g(s)\):
$$w(t,s) = f(t) + g(s)$$
For now we’ll ignore f, and just consider g. This is a simple linear function \(g(s) = s*w\). The gradient \(w\) describes how much their weight increases for each day it’s been since dialysis.
We could estimate this from previous data from that patient (e.g. by fitting a Gaussian Process model to the data). But if the patient is new, we might want to provide a prior distribution on this parameter. We could get this by considering what gradient other similar patients have (e.g. those with the same age, vintage, gender, weight, comorbidity, etc might have a similar gradient).
Side note: Colleagues have recommended that we combine all the patients into one large coregionalised model. This has several problems: excessive computational demands, privacy (having to share the data), interpretability (the gradient might be a useful feature), etc.
Other side note: I plan on fitting another model, of gradients wrt patient demographics etc to make predictions for the priors of the patients.
So our model is: \(g(s) = \phi(s)w\) where we have a prior on \(w \sim N(\mu_p, \sigma_p^2)\).
If we find the mean and covariance of \(g(s)\):
\(E[g(s)] = \phi(s) E[w] = \phi(s) \mu_p\)
\($E[g(s)g(s’)] = \phi(s) E[ww^\top] \phi(s’) = \phi(s) (\mu_p \mu_p^\top + \Sigma_p) \phi(s’)\)
It seems a simple enough problem – but it does require than the prior mean is no longer zero (or flat wrt the inputs). I’m not sure how to do that in GPy.
Update: There is no way of doing this in GPy by default. So I solved this by adding a single point, with a crafted noise, to produce or ‘induce’ the prior we want.
I’ve written this into a simple python function (sorry it’s not on pip, but it seems a little too specialised to pollute python module namespace with). Download from <a href=”https://github.com/lionfish0/experimentation/blob/master/linear_kernel_prior.py”>github</a>. The docstring should explain how to use it (with an example).
My talk at DSA2017 and the website (with realtime predictions of Kampala’s air quality)
By default it seems GPy doesn’t subtract the mean of the data prior to fitting.
So it’s worth including a mean function that does this:
m = GPy.models.GPRegression(
X,
y,
mean_function=GPy.mappings.Constant(
input_dim=1,output_dim=1,value=np.mean(y))
)
Then one needs to fix this value:
m.mean_function.C.fix()
A few notes from my visit to the city:
Tuesday: Arrived. A brief period of moderate panic on the plane when I thought I wouldn’t be let in without an electronic visa. But as of July 2017 people can still buy a single entry visa on entry. Had dinner down at Club 5. I think maybe it’s not as good as I remember!

From left to right: Ssekanjako John, the bodaboda driver; me; Engineer Bainomugisha.
Wednesday: Engineer and Joel took me on a tour ’round Kampala to visit the sites where they’ve got air pollution monitors up. We first met the bodaboda driver who’s hosting one of the sensors on his motorbike. He’s had a bit of hassle from security asking what the box is, but he’s disguised it by painting it black and half hiding it under a shredded old bin bag!

Sensor on Jinja Road
The sensor on Jinja Road looks like it’ll be measuring quite a bit – it was surrounded by traffic regularly pumping out black smoke. I suspect that, of the pollution from vehicle emissions, the majority will be from a small proportion of vehicles…
A more sobering part of the tour was to the large dump, north of the Northern Bypass. There we saw hundreds of people (some with huts built in the dump itself) sorting through the rubbish looking for recyclables. I didn’t see much evidence of PPE.

Kampala’s main dump
The main source of particulate pollution here will probably be the dirt tracks but I suspect it will be quite low (there’s very little rubbish burning apparently, when we asked around). More concerning are gas and volatile organics. I imagine ground water is contaminated too.
Thursday: Block B was shut today as the government had rented it (I wonder who got the cash??!) to do interviews for parliamentary positions. Awkward as the lab with our equipment is in there. I got to hear a few presentations at the AI Lab though, and it was good to catch up with everyone.
I took a brief bit of time from working to visit the art gallery on campus. If anyone’s visiting Kampala and has a spare half-hour, I’d recommend it!
Friday: We got a monitor working on block B outside the lab’s window. It’s having trouble with its powersupply, so it’s somewhat erratic at the moment. I got the website up and running.
For old-times sake I went down to Mediterraneo for dinner. It still seems to be going strong, and has a nice vibe in the evening.
Next: Arusha!

A Marabou Stork (Image from wikimedia)
Back at Makerere working on the air pollution monitoring project with Engineer Bainomugisha.
One of my favourite things at Makerere is sitting at a table outside the guest house, with a cup of “African Spiced Tea”, watching the Marabou storks.
We’ve just held the July GPy hack day. Key outcome: we’re going to be building the documentation in a brand new user-friendly way, based on sk-learn’s style, and using Tania’s new system for turning a bunch of notebooks into a website. Other notes from the meet. More on this soon…
I’ve finally got differential privacy for Gaussian processes on pip.
pip install dp4gp
Details and notes are in the development repo, and the paper it is based on is here. Although since then I’ve introduced inducing inputs, which appears to massively improve the results (see also presentation). The figures below demonstrate the scale of the DP noise added without and with inducing inputs.
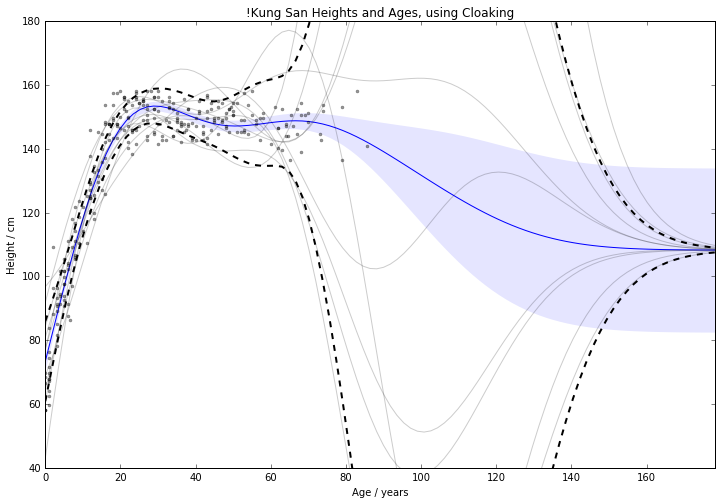
Standard cloaking method

Cloaking method with inducing inputs
A quick post to link to a jupyter notebook demonstrating how to download a whole dataset. Here’s the code. It simply hops 7999 entries at a time, downloading all the records that fall between the two ends of each step.
import json, requests from datetime import datetime, timedelta apiurl = 'http://thingspeak.com/channels/241694' nextid = 1 result = None alldata = [] endtime = None while result != '-1': print nextid result = json.loads(requests.post(apiurl+'/feeds/entry/%d.json' % nextid).content) starttime = endtime if result == '-1': endtime = datetime.now() else: endtime = datetime.strptime(result['created_at'],'%Y-%m-%dT%H:%M:%SZ') if (nextid==1): starttime = endtime else: start = datetime.strftime(starttime,'%Y-%m-%dT%H:%M:%SZ') end = datetime.strftime(endtime-timedelta(seconds=1),'%Y-%m-%dT%H:%M:%SZ') data = json.loads(requests.post(apiurl+'/feeds.json?start=%s&end=%s' % (start,end)).content) print nextid, len(data['feeds']) alldata.extend(data['feeds']) nextid += 7999 #thought download was 8000 fields, but it's 8000 records. 8000/len(result)
© 2019 Mike's Page
Theme by Anders Noren — Up ↑
{kind=link}